
Google’s MUVERA Algorithm: Revolutionizing Efficient and Contextual Search

Google’s MUVERA (Multi-Vector Retrieval Algorithm) improves information retrieval by combining the accuracy of multi-vector models with the efficiency of single-vector systems.
It simplifies complex multi-vector comparisons into streamlined single-vector searches, enabling faster and more relevant results while supporting scalability for large-scale applications.
Google’s search algorithms continue to evolve, with MUVERA (Multi-Vector Retrieval Algorithm) announced in June 2026 as the latest advancement. This algorithm addresses the computational cost of multi-vector models while maintaining higher accuracy than traditional single-vector methods.
MUVERA introduces techniques that make semantic search feasible at web scale, improving how search engines process complex queries.
Key Points
- Research identifies MUVERA as a Google-developed algorithm for efficient multi-vector retrieval in search systems.
- MUVERA likely improves retrieval speed and handles complex queries more effectively.
- Available evidence suggests its applications include search engines, recommender systems, and natural language processing.
What is MUVERA?
MUVERA (Multi-Vector Retrieval Algorithm) is a search technology developed by Google to improve both speed and accuracy, particularly for complex queries.
It simplifies how search engines process multiple representations of information, delivering results as efficiently as simpler retrieval methods.
MUVERA: Multi-Vector Retrieval at Single-Vector Efficiency
MUVERA (Multi-Vector Retrieval Algorithm) is a new retrieval method developed by Google Research that improves the efficiency of handling complex queries.
Announced in June 2026, it makes multi-vector retrieval nearly as efficient as single-vector search.
Understanding Vector Embeddings and Search Architecture
Modern information retrieval systems rely on vector embeddings, which convert text into mathematical representations that reflect semantic relationships. These embeddings allow systems to measure similarity by mapping related concepts closer together in a multi-dimensional space.
For example, a 3D visualization of an embedding space illustrates how a query for “thrash rock” retrieves similar artists, such as Metallica, Anthrax, and Slayer, based on spatial proximity.
The core idea behind vector-based retrieval is to map both queries and documents into a shared embedding space, where semantic similarity corresponds to distance in this space. Traditional keyword search relies on exact term matching, often overlooking context and intent. In contrast, embedding-based semantic search can surface relevant content even if it does not contain the actual query terms.
Advanced systems, such as MUVER, utilize multi-stage architectures that refine search results in successive steps. These pipelines typically combine sparse and dense retrieval, multi-vector processing, and re-ranking components, often integrating with large language models (LLMs) to deliver final outputs.
Technical Architecture and Core Innovation
The Multi-Vector Challenge
Multi-vector models, such as ColBERT, create multiple embeddings per query or document—typically one per token—to capture semantic details. While this improves retrieval accuracy, it introduces substantial computational overhead. Chamfer similarity, used in many of these systems, requires expensive matrix operations that make large-scale deployment difficult.
Fixed Dimensional Encoding (FDE): MUVERA’s Core Innovation
MUVERA addresses this challenge with Fixed Dimensional Encoding (FDE), which converts multi-vector sets into single fixed-length vectors. This transformation retains critical similarity signals, enabling the use of efficient Maximum Inner Product Search (MIPS) algorithms.
The FDE process partitions the embedding space and combines vectors within each partition to produce unified representations. This method is data-oblivious and independent of specific datasets, making it suitable for streaming applications. Unlike learned single-vector encoders, FDEs offer theoretical guarantees for approximating Chamfer similarity within a defined error margin.
Two-Stage Retrieval Process
MUVERA uses a two-stage pipeline that balances speed and accuracy:
Stage 1: Candidate Retrieval
- Transforms documents and queries into FDE vectors
- Uses MIPS to scan large corpora quickly
- Identifies promising candidates with minimal compute cost
Stage 2: Re-ranking
- Applies exact multi-vector similarity scoring
- Uses original Chamfer matching for precision
- Refines results for the final output
Performance Analysis and Benchmarking
Comparative Metrics
MUVERA outperforms previous systems like PLAID across key dimensions:
- 10% improvement in recall
- 90% reduction in latency
- 2–5× fewer candidates retrieved, lowering compute overhead
BEIR Benchmark Results
Across the BEIR benchmark suite, MUVERA consistently surpasses both PLAID and single-vector baselines. It shows powerful performance on complex queries and long-tail content, where contextual understanding is critical.
Memory Efficiency and Scalability
MUVERA achieves high memory efficiency using product quantization (e.g., PQ-256-8), compressing memory usage by up to 32× while maintaining accuracy. Real-world deployments report around 70% memory reduction compared to traditional multi-vector systems.
Integration with Google’s Search Infrastructure
Relationship to Existing Models
MUVERA may represent an evolution of technologies like RankEmbed, which uses dual encoders for queries and documents. While RankEmbed performs well on common queries, it struggles with edge cases. MUVERA’s multi-vector approach improves performance in those scenarios.
It complements models such as RankBrain, DeepRank (BERT), and NavBoost—components of Google’s ranking pipeline that work together to interpret and rank queries in real time.
Neural Network Foundations
MUVERA builds on deep learning foundations, particularly transformer-based models, and sophisticated embedding strategies. These architectures enable efficient learning of contextual representations, which MUVERA then compresses and scales using FDE.
Applications and Implementation Status
Current Adoption
While Google has not confirmed MUVERA’s deployment in live search, the algorithm is designed for web-scale use. Other organizations are already applying it. For example, Weaviate integrated MUVERA-style encoding in version 1.31 of its vector database.
Broader Use Cases
Beyond web search, MUVERA applies to:
- Content recommendation systems (e.g., YouTube)
- NLP tasks requiring semantic document understanding
- Enterprise search across technical or domain-specific corpora
Core Problem MUVERA Solves
Multi-vector models represent each data point with multiple embeddings, improving accuracy in retrieval tasks. However, they introduce significant computational challenges.
- Large embedding sets per token increase memory and compute demands
- Similarity scoring relies on expensive matrix operations
- No effective sublinear search methods for high-dimensional vector sets
- Significantly higher computational costs than single-vector systems
How MUVERA Works
MUVERA addresses these issues through Fixed Dimensional Encodings (FDE):
- Vector Transformation: Converts multi-vector representations into single, fixed-size vectors
- Efficient Search: Uses optimized Maximum Inner Product Search (MIPS) for initial candidate retrieval
- Re-ranking: Applies exact multi-vector similarity to refine top results
Google’s MUVERA Algorithm
Google’s MUVERA algorithm makes multi-vector retrieval as efficient as single-vector retrieval by converting sets of token-level embeddings into fixed-dimensional vectors called Fixed Dimensional Encodings (FDEs).
The inner product between FDEs approximates actual multi-vector similarity, such as Chamfer similarity. This approach enables the use of optimized single-vector Maximum Inner Product Search (MIPS) solvers during the initial retrieval phase.
Why MUVERA Matters
MUVERA improves the ability to retrieve specific information from large datasets. It is likely used in systems such as Google Search, YouTube recommendations, and natural language tools.
Designed for speed and efficiency, it enhances how search systems respond to detailed or complex queries.
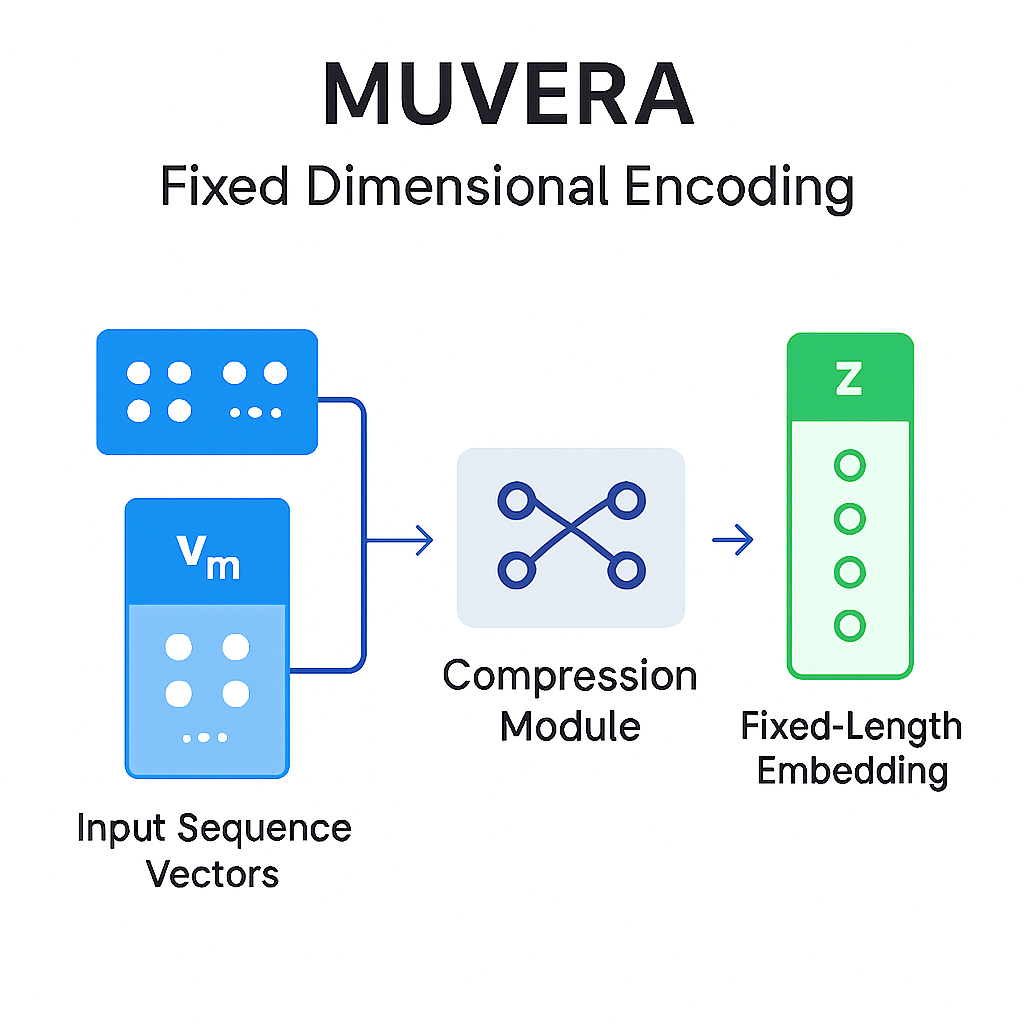
MUVERA Fixed Dimensional Encoding Process Diagram
Technical Insight
MUVERA uses Fixed Dimensional Encodings (FDEs) to convert complex, variable-length data into compact, consistent formats that computers can process efficiently. Research indicates it achieves up to 90% faster performance with improved accuracy compared to previous methods.
Background and Purpose
MUVERA (Multi-Vector Retrieval Algorithm) addresses a core challenge in modern information retrieval: the computational inefficiency of multi-vector (MV) models.
Architectures like ColBERT improve retrieval performance by using multiple embeddings per data point to capture fine-grained semantic details.
However, these models are costly to run due to the need for complex similarity calculations, such as Chamfer similarity, across sets of vectors.
MUVERA simplifies this process by converting multi-vector similarity search into single-vector (SV) similarity search. This allows the use of optimized Maximum Inner Product Search (MIPS) algorithms.
The goal is to make MV models scalable and efficient enough for real-world applications, including search engines, recommender systems, and natural language processing (NLP) tasks.
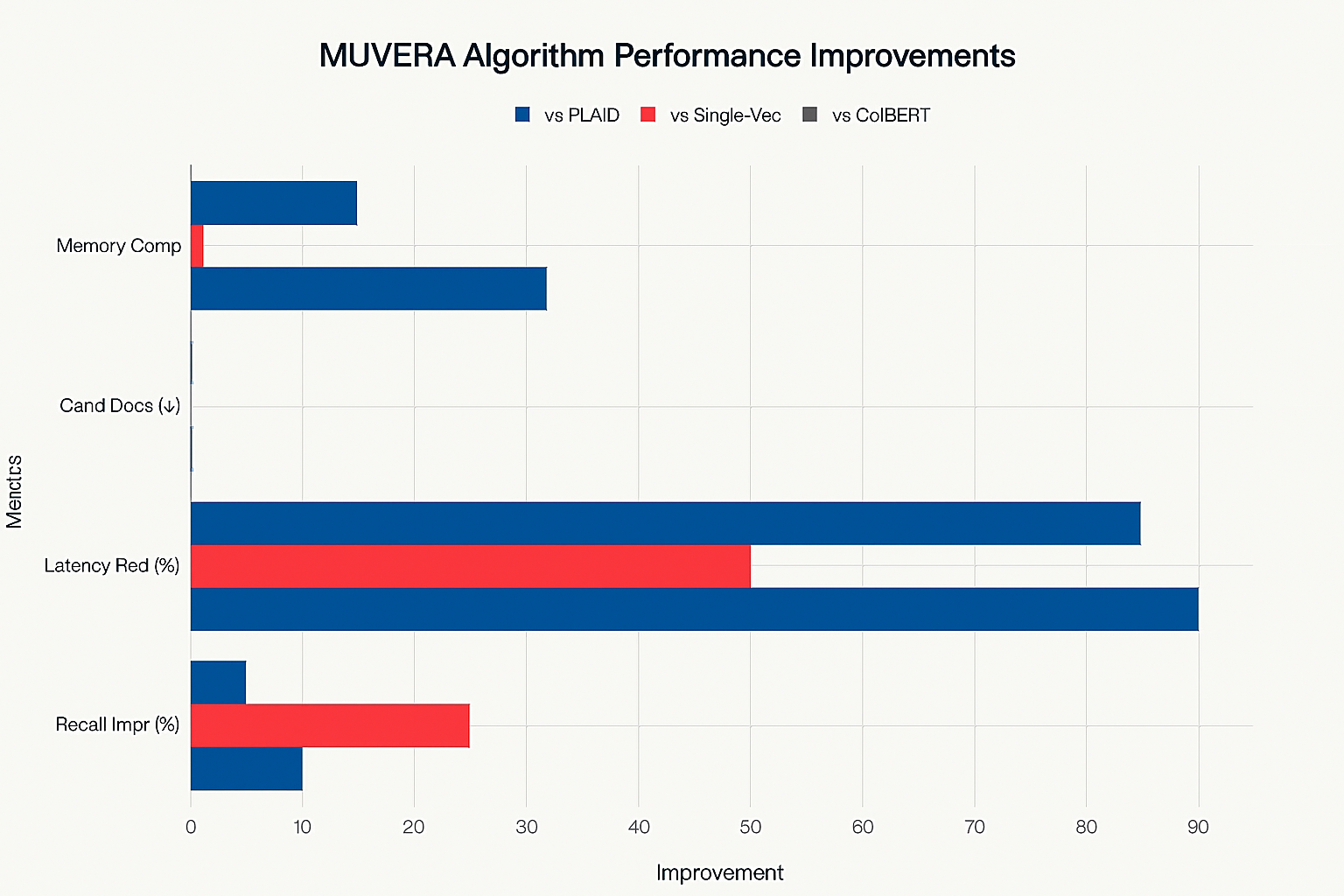
MUVERA Algorithm Performance Improvements Across Key Metrics
Empirical Performance and Optimizations
Evaluations on BEIR benchmark datasets show that MUVERA delivers strong performance across key metrics:
Recall and Latency
MUVERA improves recall by 10% and reduces latency by 90% compared to PLAID, a prior state-of-the-art method. It also matches the recall of single-vector heuristics while retrieving 2 to 5 times fewer candidates.
Memory Efficiency
Fixed Dimensional Encodings (FDEs) can be compressed using product quantization techniques, such as PQ-256-8, achieving 32× compression with minimal loss in retrieval accuracy.
This compression significantly increases queries per second (QPS), with up to a 20× improvement observed.
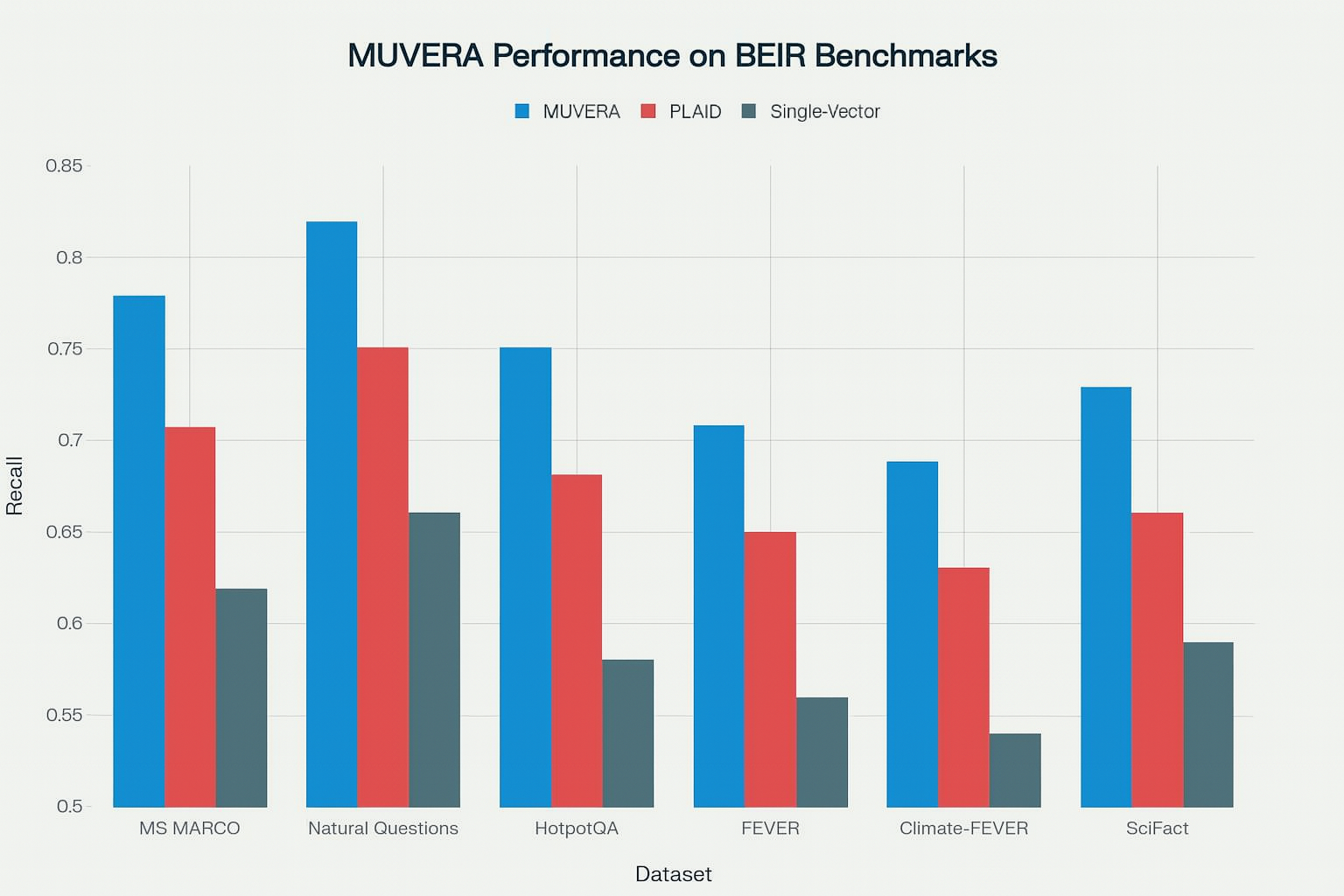
MUVERA Performance on BEIR Benchmark Datasets
Optimizations
- DiskANN: Used for MIPS retrieval. Beam width (W) can be adjusted to balance recall and latency.
- Ball Carving: Reduces query embeddings. For example, a 5.4× reduction at threshold τ = 0.7 results in negligible loss of recall.
- Product Quantization: Compresses FDEs to support faster retrieval with minimal accuracy tradeoff.
These optimizations enable MUVERA to scale effectively in large retrieval systems, addressing both compute and memory constraints.
Practical Applications and Adoption
MUVERA is used not only in search engines but also in recommender systems (such as YouTube) and natural language processing tasks.
Its ability to manage complex queries that require fine-grained semantic understanding makes it well-suited for modern information retrieval pipelines.
Companies like Weaviate have adopted MUVERA, with version 1.31 integrating the algorithm for multi-vector embeddings.
Comparative Analysis
Compared to earlier methods such as PLAID, MUVERA achieves lower latency and higher recall, especially on large datasets.
Its data-oblivious design and theoretical guarantees set it apart from heuristic-based systems, offering a more reliable solution for dynamic and streaming applications.
The Shift from Single-Vector to Multi-Vector Retrieval
Traditional single-vector models, such as RankEmbed, encode queries and documents into single dense vectors. This design enables fast retrieval using Maximum Inner Product Search (MIPS) algorithms. However, these models face two key limitations:
- Limited semantic resolution: They struggle to capture fine-grained relationships between query components and document elements.
- Poor performance on tail queries: They show reduced accuracy for complex, specific, or low-frequency queries.
Multi-vector models, including ColBERT, address these issues by representing each input as multiple token-level embeddings.
These models use Chamfer matching (MaxSim), which measures the maximum similarity between each query token and its closest matching document token.
While they achieve 10–15% higher accuracy than single-vector models, they introduce new challenges:
- High computational cost: Scoring requires O(n|Q||P|) operations, where n is the number of documents, Q is the document count, and P is the token count for documents.
- Infrastructure inefficiencies: They are not compatible with existing optimized MIPS solvers.
Technical Innovation: Fixed Dimensional Encodings (FDEs)
MUVERA introduces an asymmetric encoding strategy that transforms variable-length multi-vector sets into fixed-length vectors while preserving Chamfer similarity relationships.
The MUVERA Retrieval Pipeline
FDE Indexing Phase
- Precompute document FDEs offline.
- Index the resulting vectors using optimized MIPS solvers such as DiskANN or FAISS.
Query Processing
- Convert each query into an FDE, with approximately 1 millisecond latency.
- Retrieve top-K candidate documents using approximate MIPS.
Re-ranking
- Apply exact Chamfer similarity to the top candidates only.
- This selective computation reduces load, applying full scoring to less than 1% of the corpus.
MUVERA Performance Comparison
| Metric | PLAID (ColBERTv2) | SV Heuristic | MUVERA | Improvement |
|---|---|---|---|---|
| Recall@100 | Baseline | 15–20% lower | +10% average | 10% higher recall |
| Latency | 100% (reference) | ~50% lower | 90% lower | 10× faster |
| Candidate Efficiency | N/A | 300–1200 docs | 60 docs | 5–20× fewer candidates |
| Memory Footprint | High | Medium | 32× compressible | PQ-256-8 compression method |
Performance and Efficiency Gains
Evaluations on BEIR benchmark datasets (MS MARCO, HotpotQA, NQ, and others) highlight MUVERA’s measurable improvements:
Accuracy Improvements
- Achieves 10% higher average recall compared to PLAID, a leading optimized multi-vector system.
- Matches the recall of brute-force multi-vector methods while requiring 5–20× fewer candidates than single-vector heuristics.
Efficiency Gains
- Reduces latency by 90% compared to PLAID, while improving recall.
- Achieves 32× compression using product quantization (PQ-256-8) with less than 2% drop in recall.
- Increases throughput, enabling 20× more queries per second (QPS).
Operational Benefits
- Removes the need for multi-stage tuning.
- Supports a consistent configuration across varied datasets.
Practical Applications and SEO Implications
Beyond Web Search
- YouTube recommendations: Efficiently matches user context to video content.
- Cross-modal retrieval: Supports unified search across image, video, and text inputs.
- Real-time conversational AI: Enables low-latency handling of complex user queries.
SEO Implications
MUVERA supports a shift from keyword-based strategies to intent-focused optimization:
- Keyword repetition loses value. Content must address the whole intent behind the entire intention.
- For example, in the query “corduroy jackets men’s medium”, search systems prioritize product pages over keyword-stuffed articles.
New content optimization priorities include:
- Contextual coverage: Address all relevant aspects of the topic.
- Direct query resolution: Provide clear answers to both explicit and implied questions.
- Entity modeling: Capture and relate key concepts within the content to facilitate understanding.
SEO and Digital Marketing Implications
Shift from Keywords to Intent
MUVERA’s semantic capabilities mark a structural change in search optimization. Its ability to interpret context and intent reduces the effectiveness of traditional keyword-focused strategies.
Key Strategic Changes:
- Semantic Optimization: Content must clearly and comprehensively address the user intently, not just match specific keywords.
- Topic Authority: Broad, in-depth coverage of subject matter carries more weight than keyword repetition.
- Contextual Relevance: Pages that reflect an understanding of user needs are more likely to rank well.
Technical SEO Considerations
Algorithms influenced by MUVERA introduce new priorities for technical SEO:
- Structured Data: Becomes more critical for clarifying relationships between entities and topics.
- Internal Linking: Gains importance in reinforcing semantic associations across related pages.
- Content Architecture: Should mirror logical topic hierarchies to improve interpretability.
Algorithm Update Focus
Google’s 2026 updates continue to emphasize E-A-T: Expertise, Authoritativeness, and Trustworthiness. Content that demonstrates subject mastery and provides meaningful value to users is increasingly favored in ranking systems.
Future Directions and Challenges
- Dynamic Partitioning: Implement adaptive clustering that adjusts to shifts in data distribution.
- Cross-Modal FDEs: Develop unified encodings across text, image, and audio for multimodal retrieval.
- Hardware Optimization: Accelerate FDE generation using GPU or TPU-based implementations.
- Query-Aware FDEs Design encoding strategies that adjust based on query structure and complexity.
The open-source release of the FDE implementation on GitHub reflects Google’s commitment to advancing retrieval systems through public collaboration.
As MUVERA becomes integrated into Google’s infrastructure, it sets a technical standard that achieves both semantic precision and operational efficiency simultaneously, redefining how machines process and retrieve human knowledge.
Key Aspects of MUVERA
| Aspect | Details |
|---|---|
| Algorithm Name | MUVERA (Multi-Vector Retrieval Algorithm) |
| Purpose | Converts multi-vector (MV) retrieval into single-vector (SV) MIPS for speed and scalability |
| Key Innovation | Fixed Dimensional Encodings (FDEs) that approximate Chamfer similarity |
| Methodology | FDE generation, retrieval using MIPS, and re-ranking with Chamfer similarity |
| Theoretical Basis | Builds on probabilistic tree embeddings, offering ε-approximation guarantees |
| Advantages | Data-oblivious design supports streaming and maintains accuracy after re-ranking |
| Implementation | Open-source FDE construction available via GitHub (Google Graph Mining) |
| Experimental Evaluation | Evaluated on BEIR benchmarks and compared with PLAID |
| Results | 10% higher recall, 90% lower latency vs. PLAID, and 32× FDE compression with product quantization |
| Collaborators | Majid Hadian, Jason Lee, Vahab Mirrokni |
| Publication Date | June 25, 2026 (Google Research Blog) |
| Authors | Rajesh Jayaram, Laxman Dhulipala (Google Research) |
This table summarizes MUVERA’s core features, performance, and contributors, providing a concise reference for its scope and impact.
Impact on Search and SEO Practices
MUVERA introduces meaningful changes to how search systems evaluate and retrieve content, influencing both search engine optimization (SEO) strategies and content discovery workflows.
By improving the processing of semantic relationships, it shifts emphasis from exact keyword matching to contextual understanding and intent-driven retrieval.
This transition encourages content creators and SEO professionals to focus on comprehensive topic coverage and natural language clarity rather than isolated keyword optimization.
MUVERA’s semantic capabilities may enhance the visibility of well-structured, in-depth content.
Its ability to process nuanced relationships efficiently can produce more varied and relevant search results, helping users access a broader range of perspectives while staying aligned with query intent.
This shift arrives as publishers face mounting challenges in adapting to AI-driven content ecosystems, as noted by Google CEO Sundar Pichai.
Beyond web search, MUVERA’s efficiency supports advanced applications such as real-time recommendation systems, personalized content delivery, and complex query interpretation.
These benefits stem from its ability to scale multi-vector retrieval without incurring high computational costs.
As more organizations adopt multi-vector models for semantic understanding, MUVERA offers a viable approach to deploying them in production environments.
Future Directions and Potential Enhancements
MUVERA advances multi-vector retrieval efficiency, but several areas remain open for further research and development.
These include extending its capabilities, improving adaptability, and enhancing transparency in model behavior.
Incorporating the Audio Modality
MUVERA has been primarily evaluated on text-based retrieval, where multi-vector embeddings are derived from tokenized text (e.g., ColBERT).
A natural extension would be to explore its use in multimodal scenarios by integrating audio data.
In video retrieval, for example, audio tracks often contain information that complements visual and textual inputs.
To support this, future work could focus on extracting audio features as multi-vector representations, analogous to token embeddings. These could then be processed through MUVERA’s FDE pipeline.
Key challenges include defining meaningful audio feature vectors and developing strategies to combine FDEs from different modalities (e.g., audio, video, text) for unified similarity search. This would support broader applications such as spoken-query search or multimodal video understanding.
Handling Dynamic and Evolving Entities
Real-world data often changes over time. New entities emerge, and existing ones evolve.
Although MUVERA’s data-oblivious FDE generation can handle distribution shifts to some extent, future work could improve its responsiveness to dynamic inputs.
One direction would be to design adaptive or incremental FDE updates.
For instance, a news retrieval system might update the representation of a public figure based on recent developments. This could involve online learning techniques or lightweight updates to embeddings and FDEs, avoiding full recomputation.
Such capabilities would benefit systems operating in real-time domains, such as news aggregation, social media tracking, or knowledge graph updates.
Improving Interpretability
Like many machine learning systems, MUVERA lacks transparency in its method of generating final rankings. In sensitive applications such as healthcare, finance, or legal document retrieval, understanding why specific documents are retrieved is essential.
Future work could explore interpretability tools for FDE-based retrieval. For example, adapting attention or attribution techniques might help identify which embeddings or features most influence a similarity score.
Visualizations or scoring breakdowns could improve trust, assist debugging, and help refine the model’s behavior for specific use cases.
Conclusion
MUVERA introduces a practical and theoretically grounded approach to efficient multi-vector retrieval. It improves search speed, recall, and latency, making it well-suited for next-generation information retrieval systems.
Its open-source availability invites further development and adoption across various applications, including search, recommendation, and language understanding.


